CNN-图像分类¶
1.CNN 图像分类 —— 从 LeNet5 到 ResNet¶
2.LeNet5¶
LeNet5 的提出:
在神经网络的和深度学习领域,Yann LeCun 在 1998 年在 IEEE 上发表了 (Gradient-based learning applied to document recognition,1998), 文中首次提出了 卷积-池化-全连接 的神经网络结构,由 LeCun 提出的七层网络命名为 LeNet-5,因而也为他赢得了 CNN 之父的美誉.
LeNet-5 的网络结构:
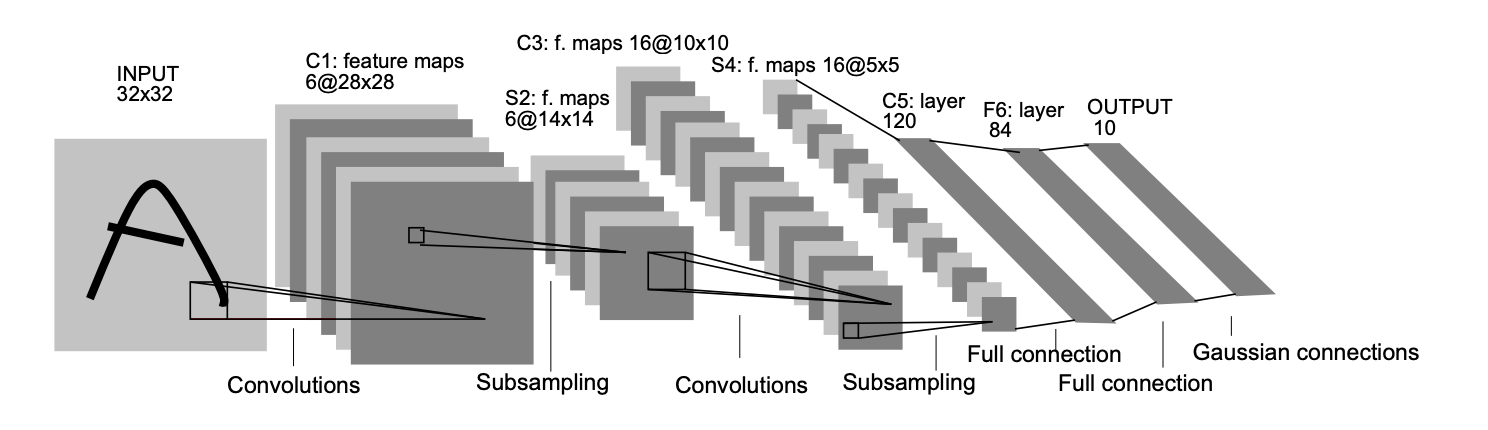
LeNet-5 共有5层(输入输出层不计入层数, 池化层与卷积层算1层). 每层都有一定的训练参数,其中三个卷积层的训练参数较多,每层都有多个滤波器(特征图),每个滤波器都对上一层的输出提取不同的像素特征:
\[输入 \rightarrow (卷积-池化) \rightarrow (卷积-池化) \rightarrow 卷积(全连接) \rightarrow 全连接 \rightarrow 全连接 \rightarrow 输出\]Note
作为标准的卷积网络结构,LeNet-5 对后世的影响深远,以至于在 16 年后,谷歌提出 Inception 网络时也将其命名为 GoogLeNet, 以致敬 Yann LeCun 对卷积神经网络发展的贡献。然而 LeNet-5 提出后的十几年里,由于神经网络的可解释性问题和计算资源的限制, 神经网络的发展一直处于低谷.
3.AlexNet¶
AlexNet 的提出:
2012年,深度学习三巨头之一的 Geoffrey Hinton 的学生 Alex Krizhevsky 率先提出了 AlexNet (ImageNet Classification with Deep Convolutional Neural Networks,2012), 并在当年度的 ILSVRC(ImageNet大规模视觉挑战赛)以显著的优势获得当届冠军,top-5 的错误率降至了 16.4%, 相比于第二名 26.2% 的错误率有了极大的提升。这一成绩引起了学界和业界的极大关注, 计算机视觉也开始逐渐进入深度学习主导的时代.
AlexNet 的网络结构:
AlexNet 共有 8 层(输入输出层不计入层数, 池化层与卷积层算1层):
\[输入 \rightarrow (卷积-池化) \rightarrow (卷积-池化) \rightarrow 卷积 \rightarrow 卷积 \rightarrow (卷积-池化) \rightarrow 全连接 \rightarrow 全连接 \rightarrow 全连接 \rightarrow 输出\]AlexNet 继承了 LeNet-5 的思想,将卷积神经网络发展到很宽很深的网络中,相较 LeNet-5 的 6 万个参数, AlexNet 包含了 6 亿 3 千万条连接,6 千万个参数和 65 万个神经元.
4.ZFNet¶
在 2013 年的 ILSVRC 大赛中,Zeiler 和 Fergus 在 AlexNet 的基础上对其进行了微调提出了 ZFNet, 使得 top5 的错误率下降到 11.2%,夺得当年的第一.
5.VGG-Net(VGG16, VGG19)¶
到了 2014 年,不断的积累实践和日益强大的计算能力使得研究人员敢于将神经网络的结构推向更深层。 在 2014 年提出的 VGG-Net (Very Deep Convolutional Networks for Large-Scale Image Recognition,2014 )中, 首次将卷积网络结构拓展至 16 和 19 层,也就是著名的 VGG16 和 VGG19。
相较于此前的 LeNet-5 和 AlexNet 的 \(5 \times 5\) 卷积和 \(11 \times 11\) 卷积,VGGNet 结构中大量使用 \(3 \times 3\) 的卷积核和 \(2 \times 2\) 的池化核。
VGGNet 的网络虽然开始加深但其结构并不复杂,但作者的实践却证明了卷积网络深度的重要性。 深度卷积网络能够提取图像低层次、中层次和高层次的特征,因而网络结构需要的一定的深度来提取图像不同层次的特征.
在论文中,作者使用了 A-E 五个不同深度水平的卷积网络进行试验,从A到E网络深度不断加深,网络的具体信息如下:
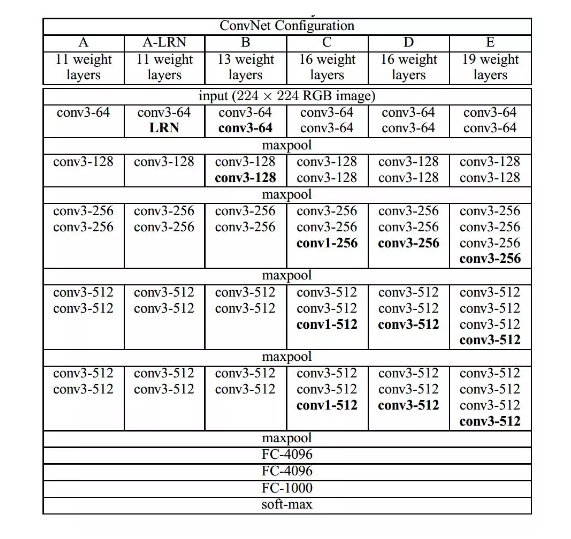
VGG 的网络结构非常规整,2-2-3-3-3的卷积结构也非常利于编程实现。卷积层的滤波器数量的变化也存在明显的规律, 由64到128再到256和512,每一次卷积都是像素成规律的减少和通道数成规律的增加。VGG16 在当年的 ILSVRC 以 32% 的 top5 错误率取得了当年大赛的第二名。这么厉害的网络为什么是第二名?因为当年有比 VGG 更厉害的网络, 也就是前文提到的致敬 LeNet-5 的 GoogLeNet.
6.GoogLeNet¶
GoogLeNet (Going Deeper with Convolutions,2014)在借鉴此前 1x1 卷积思想的基础上, 通过滤波器组合构建 Inception 模块,使得网络可以走向更深且表达能力更强。从 2014 年获得当届 ILSVRC 冠军的 Inception v1 到现在,光 Inception 网络就已经更新到 v4 了,而后基于 Inception 模块和其他网络结构的组合而成的网络就更多了,比如说 Inception Resnet。
通常在构建卷积结构时,我们需要考虑是使用 1x1 卷积、3x3 卷积还是 5x5 卷积及其是否需要添加池化操作。 而 GoogLeNet 的 Inception 模块就是帮你决定采用什么样的卷积结构。简单而言,Inception 模块就是分别采用了 1x1 卷积、 3x3 卷积和 5x5 卷积构建了一个卷积组合然后输出也是一个卷积组合后的输出。如下图所示:
对于 28x28x192 的像素输入,我们分别采用 1x1 卷积、3x3 卷积和 5x5 卷积以及最大池化四个滤波器对输入进行操作, 将对应的输出进行堆积,即 32+32+128+64=256,最后的输出大小为 28x28x256。所以总的而言,Inception 网络的基本思想就是不需要人为的去决定使用哪个卷积结构或者池化,而是由网络自己决定这些参数,决定有哪些滤波器组合。
构建好 Inception 模块后,将多个类似结构的Inception模块组合起来便是一个Inception 网络,如下图所示:
7.ResNet¶
深度卷积网络一开始面临的最主要的问题是梯度消失和梯度爆炸。那什么是梯度消失和梯度爆炸呢?所谓梯度消失, 就是在深层神经网络的训练过程中,计算得到的梯度越来越小,使得权值得不到更新的情形,这样算法也就失效了。 而梯度爆炸则是相反的情况,是指在神经网络训练过程中梯度变得越来越大,权值得到疯狂更新的情形, 这样算法得不到收敛,模型也就失效了。当然,其间通过设置 relu 和归一化激活函数层等手段使得我们很好的解决这些问题。 但当我们将网络层数加到更深时却发现训练的准确率在逐渐降低。这种并不是由过拟合造成的神经网络训练数据识 别准确率降低的现象我们称之为退化(degradation)。
何恺明等一干大佬就提出了残差网络 ResNet (Deep Residual Learning for Image Recognition,2015)。
要理解残差网络,就必须理解残差块(residual block)这个结构,因为残差块是残差网络的基本组成部分。 回忆一下我们之前学到的各种卷积网络结构(LeNet-5/AlexNet/VGG),通常结构就是卷积池化再卷积池化, 中间的卷积池化操作可以很多层。类似这样的网络结构何恺明在论文中将其称为普通网络(Plain Network), 何凯明认为普通网络解决不了退化问题,我们需要在网络结构上作出创新。
何恺明给出的创新在于给网络之间添加一个捷径(shortcuts)或者也叫跳跃连接(skip connection), 可以让捷径之间的网络能够学习一个恒等函数,使得在加深网络的情形下训练效果至少不会变差。残差块的基本结构如下:
以上残差块是一个两层的网络结构,输入 X 经过两层的加权和激活得到 F(X) 的输出,这是典型的普通卷积网络结构。 但残差块的区别在于添加了一个从输入 X 到两层网络输出单元的 shortcut,这使得输入节点的信息单元直接获得了与输出节点的信息单元通信的能力, 这时候在进行 relu 激活之前的输出就不再是 F(X) 了,而是 F(X)+X。当很多个具备类似结构的这样的残差块组建到一起时, 残差网络就顺利形成了。残差网络能够顺利训练很深层的卷积网络,其中能够很好的解决网络的退化问题。
或许你可能会问凭什么加了一条从输入到输出的捷径网络就能防止退化训练更深层的卷积网络?或是说残差网络为什么能有效? 我们将上述残差块的两层输入输出符号改为和,相应的就有:
在网络中加入 L2 正则化进行权值衰减或者其他情形下,l+2 层的权值 W 是很容易衰减为零的,假设偏置同样为零的情形下就有 =。 深度学习的试验表明学习这个恒等式并不困难,这就意味着,在拥有跳跃连接的普通网络即使多加几层,其效果也并不逊色于加深之前的网络效果。 当然,我们的目标不是保持网络不退化,而是需要提升网络表现,当隐藏层能够学到一些有用的信息时,残差网络的效果就会提升。 所以,残差网络之所以有效是在于它能够很好的学习上述那个恒等式,而普通网络学习恒等式都很困难,残差网络在两者相较中自然胜出。
由很多个残差块组成的残差网络如下图右图所示:
ResNet 在 2015 年 ILSVRC 大赛上 top5 单模型的错误率达到了 3.57%,在其他数据集上也有着惊人的表现。